Prelude
This blog post is based on the lecture notes I prepared for one of the courses in which I am the teaching assistant. Hopefully, this notes will be useful for anyone interested in either Approximate Query Processing (AQP) or basic Sampling theory as applied in Databases.
Approximate Query Processing
Consider a database D which contains billions of tuples. Such a large database is not uncommon in data warehousing. When we want to get some answers from the database, we construct a SQL query to get the results. Due to the large size of the database, any query should take quite a bit of time. This is regardless of the use of techniques like indexing which can speed up the processing time but does not really reduce the time asymptotically.
One observation is that the queries that are posed to the database returns very precise and accurate answers – probably after looking at each and every tuple. For a lot of use cases of OLAP we may not need such a precise answer. Consider some sample queries like – what is the ratio of male to female in UTA ? What percentage of US people live in Texas? What is the average salary of all employees in the company? and so on.
Notice that for such queries we really do not need answers that are correct to the last decimal point. Also notice that each of those query is an aggregate over some column. Approximate query processing is a viable technique to use in these cases. A slightly less accurate result but which is computed instantly is desirable in these cases. This is because most analysts are performing exploratory operation on the database and do not need precise answers. An approximate answer along with a confidence interval would suit most of the use cases.
There are multiple techniques to perform approximate query processing. The two most popular involve histograms and sampling. Histograms store some statistic about the database and then use it to answer queries approximately. Sampling creates a very small subset of the database and then uses this smaller database to answer the query. In this course we will focus on AQP techniques that use sampling. Sampling is a very well studied problem backed up by a rich theory that can guide us in selecting the subset so that we can provide reasonably accurate results and also provide statistical error bounds.
Introduction to Sampling
The idea behind sampling is very simple. We want to estimate some specific characteristic of a population. For eg this might be the fraction of people who support some presidential candidate or the fraction of people who work in a specific field or fraction of people infected with a disease and so on. The naive strategy is to evaluate the entire population. Most of the time , this is infeasible due to constraints on time, cost or other factors.
An alternate approach that is usually used is to pick a subset of people . This subset is usually called a sample. The size of the sample is usually an order of magnitude smaller than the population. We then use the sample to perform our desired evaluation. Once we get some result, we can use this to estimate the characteristic for the entire population. Sampling theory helps, among other things, on how to select the subset , what is the size of population, how to extrapolate the result from sample to original population , how to estimate the confidence interval of our prediction etc.
The process of randomly picking a subset of the population and using it to perform some estimation should appear very strange. On a first glance it might look that we might get wildly inaccurate results. We will later see how to give statistical guarantees over our prediction. Sampling is a very powerful and popular technique. More and more problems in the real world are being solved using sampling. Lots of recent problems in data mining and machine learning essentially use sampling and randomization to approximately solve very complex problems which are not at all solvable otherwise. This is for this reason that most DBMS provide sampling as a fundamental operator. (Eg Oracle provides a SAMPLE operator in select and also dbms_stats package. SQL Server provides TABLESAMPLE operator and so on).
We represent the population with P and the sample with S. N represents the size of population and n represents the size of the sample. We will use these letters to denote statistics on the population and sample. For eg, 

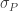

Types of Sampling
There are different ways to perform sampling. The ones that we will use most in AQP are :
Sampling With/Without Replacement
The aim of sampling is to get a subset (sample) from a larger population. There are two ways to go about it. In the first approach, we randomly pick some entity, perform measurements if any and add it to the sample. We then replace the entity back to the original population and repeat the experiment. This means that same entity can come in the sample multiple times. This approach is called Sampling with replacement. This is the simplest approach to sampling. There is no additional overhead to check if an entity is already in sample or not. Typically, sampling with replacement is modeled with binomial distribution.
In the second approach, we explicitly make sure that an entity does not appear in the sample more than once. So we randomly pick an entity from the population, verify it is not already in the sample, perform measurement and so on. Alternatively, we can remove entities that were added to sample from the population. This approach is called Sampling without replacement and is usually modeled with an hypergeometric distribution.
Bernoulli Sampling
Bernoulli Trial : A Bernoulli Trial is an experiment which has exactly two outcomes – Success or failure. Each of these outcomes has an associated probability that completely determines the trial. For eg consider a coin which produces head with probability 0.6 and tail with probability 0.4 . This constitutes a bernoulli trial as there are exactly two outcomes.
In Bernoulli Sampling, we perform a Bernoulli trial on each tuple in the database. Each tuple can be selected into a sample with uniform probability. If the trial is a success, the tuple is added to the sample. Else it is not. The most important thing to notice is that all the tuples have exactly the sample probability of getting into the sample. Alternatively, the success probability for Bernoulli trial remains the same for each tuple. Pseudo code for Bernoulli Sampling is given below :
success probability SP =

for i = 1 to N
Perform a Bernoulli trial with success probability SP
If outcome is success add i-th tuple to sample
It is important to note that Bernoulli sampling falls under Sampling without replacement. Size of the sample follows a binomial distribution with parameters 
Uniform Random Sampling
In Uniform Random Sampling, we pick each tuple in the database with a constant probability. This means that the probability of any tuple entering the sample is constant. Typically, this is implemented as sampling with replacement. Pseudo code for Uniform Random Sampling is given below :
1. Generate a set of n random numbers S between 1 and N.
2. Select tuples with index in S and add it to sample.
Note that in this case we have exactly n tuples in the sample. We can also notice that sample tuple might appear multiple times. The number of times a tuple appears in the sample forms a binomial distribution with parameters 
Weighted Random Sampling
In Weighted Random Sampling, we perform a Bernoulli trial on each tuple in the database. The difference with Uniform random sampling that the success probability for each Bernoulli trial varies. In other words, each tuple has a different probability of getting into the sample.
Stratified Sampling
If the population can be subdivided into sub population that are distinct and non overlapping , stratified sampling can be used. In Stratified sampling, we split the population into a bunch of strata and then form sampling over each strata independently. For eg a political poll can be stratified on gender, race , state etc.
There are multiple advantages in using stratified sampling. For one, this allows the convenience to use different sampling techniques over each strata. If there is some specific strata that might be under represented in a general random sampling, we can easily provide additional weights for the samples taken from that. It is also possible to vary the number of samples from a strata to minimize the error. For eg, we can take less number of samples from a strata with low variance while preserving them for strata with high variance.
Stratified sampling is not a panacea because getting a good stratification strategy may not be obvious. In lot of population, the best feature to stratify is not obvious. Even worse, the population may not contain subgroups that are homogeneous and non overlapping.
Given a population , sample size and strata there are many ways to allocate the sample across different strata. The two commonly used strategies are :
1. Proportional Allocation : In this approach the contribution of each strata to the sample is proportional to the size of the strata. So a strata that accounts to 10\% of the population will use 10\% of the sample. Note that this approach does not use any information about a sub population other than its size.
2. Variance based Allocation : This strategy allocates samples in proportion to their variance. So a strata with high variance will have higher representation than one with smaller variance. This is logical as we need few samples to accurately estimate the parameters of a sub population when its variance is low. Any additional samples do not add much additional information or reduce the final estimation dramatically.
Reservoir Sampling
Reservoir Sampling is an algorithm that is widely used to take n random samples from a large database of size N. The real utility of reservoir sampling is realized when N is a large number or is not really known at sample time. This scenario is quite common when the input is a streaming data or when the database is frequently updated . Running the simple uniform random sampling algorithm (say Bernoulli sampling) is inefficient as N is large or the old tuples may be purged (or goes out of Sliding Window). Reservoir sampling allows you to get the random sample in a linear pass such that you only inspect any tuple at most once.
Reservoir Sampling with Single Sample
Consider the following contrived example. We have a database which is constantly updated and we want to have a single random tuple from it.
The base case occurs when there is only one tuple in the database. In this case our random sample is the first tuple. Hence the sample S = t1.
Lets say the database is updated and a new tuple t2 is added. The naive approach is to restart the entire sampling process. Instead, in reservoir sampling, we accept the new tuple as the random sample with probability 
We can see why S is a uniform sample. The probability that S contains t1 or t2 remains the same.
1. 

2. 
The database is updated and lets assume a new tuple t3 is added. We accept the new tuple as the random sample with probability 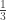

It might look as if we are treating t3 unfairly because we only accept it with probability 0.33. But we can show probabilistically that the sample is still uniform. The probability that S is t1 or t2 or t3 remains the same.
1. 

2. 
3. 
The pseudo code looks like :
S = t1
for i = 2 to N
Replace S with tuple t_i with probability
Reservoir Sampling with Multiple Samples
A very similar approach works when the sample size is more than 1. Lets say that we need a sample of size n. Then we initially set the first n tuples of the database as the sample. The next steps is a bit different. In the previous case, there was only one sample so we replaced the sample with the selected tuple. When sample size is more than 1, then this steps splits to two parts :
1. Acceptance : For any new tuple t_i, we need to decide if this tuple enters the sample. This occurs with probability 
2. Replacement : Once we decided to accept the new tuple into the sample, some tuple already in the sample needs to make way. This is usually done randomly. We randomly pick a tuple in the sample and replace it with tuple t_i.
The pseudo code looks like :
Store first n elements into S
for i = n+1 to N
Accept tuple t_i with probability
If accepted, replace a random tuple in S with tuple t_i
A coding trick that avoids the "coin tossing" by generating a random index and then accepts it if it is less than our sample size. The pseudo code looks like :
Store first n elements into S
for i = n+1 to N
randIndex = random number between 1 and i
if randIndex <= n
replace tuple at index "randIndex" in the sample with tuple t_i
We can similarly analyze that the classical reservoir sampling does provide a uniform random sample. Please refer to the paper Random Sampling with a Reservoir by Jeffrey Vitter for additional details.
Sampling in AQP
As discussed above, our main aim is to discuss how sampling techniques is used in AQP. Let us assume that we have a sample S of size n. The usual strategy that we will follow is to apply any aggregate query on the sample S instead of database D. We then use the result of the query from S to estimate the result for D.
One thing to note is that we will only use aggregate queries for approximate processing. Specifically we will look at COUNT, SUM and AVERAGE. The formulas for estimating the values of the aggregate query for the entire database from the sample for these 3 operators is well studied. For additional details refer to the paper “Random Sampling from Databases" by Frank Olken.
Uniform Random Sample
1. Count : 


2. Sum : 
3. Average : 
\end{itemize}
Weighted Random Sample
1. Count : 
2. Sum : 
3. Average :
Probability/Statistics Refresher
Here are few commonly used equations related to Expectation and variance.
1. E[X] = 
2. E[aX+b] = aE[X] + b
3. E[X+Y] = E[X] + E[Y] (also called Linearity of Expectations)
4. Var[X] = ![E[ (X - E[X] ) ^2]](https://s0.wp.com/latex.php?latex=E%5B+%28X+-+E%5BX%5D+%29+%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
5. Var[X+a] = Var[X]
6. Var[aX] = 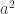
7. Var[X+Y] = Var[X] + Var[Y] if X and Y are independent.
Law of Large Numbers : This law is one of the fundamental laws in probability. Let 
Binomial Distribution: Suppose you repeat a Bernoulli trial with success probability of p , n times. The distribution of the number of successes in the n trials is provided by binomial distribution B(n,p). This is a very important distribution for modeling sampling with replacement. For eg if we perform Bernoulli sampling, the final size of the sample is a Binomial distribution. Also if we randomly pick n tuples from database of size N , the number of times any tuple is repeated in the sample can also modeled by Binomial distribution. The expected value is given by ![E[X]=np](https://s0.wp.com/latex.php?latex=E%5BX%5D%3Dnp&bg=ffffff&fg=333333&s=0&c=20201002)

Normal Distribution : Normal distribution , aka Gaussian distribution, is one of the most important probability distributions. It is usually represented with parameters 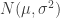


Equations (2) and (7) above gives us some detail about how expected value and variance of sum of two random variables can be computed from the expected value/variance of the constituent random variables . We can extend by induction for the rules to hold for the sum of arbitrarily large number of random variables. This introduces us to the concept of Central Limit Theorem.
Central Limit Theorem : This is one of the most fundamental rules in probability. Assume that we have n different random variables 



Law of large numbers and Central limit theorem are two important results that allow analysis of the results. law of large number says that if we pick a large enough sample then the average of the sample will be closer to the true average of population. Central limit theorem states that if you repeat the sampling experiment multiple times and plot the distribution of the average value of the samples, they follow a normal distribution. Jointly, they allow you to derive the expression for Standard error.
Standard Error
The essential idea behind sampling is to perform the experiment on a randomly chosen subset of the population instead of the original population. So far we discussed how to perform the sampling and how to estimate the value from sample to the larger population. In this section let us discuss about the error in our prediction. The concept of standard error is usually used for the same.
Lets say we want to estimate the mean of the population
1. Absolute Error : 
2. Relative Error : 
The primary problem we have in estimating these error metrics is that we do not know the value of
Consider the sampling process again. We picked a sample 

Let the population 



Standard Error when Sample Size = 1
Consider the case where the sample S consists of only one element. Our aim is to find population mean. As per our approach, we pick a random element 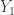

We can derive the expected value for the error as follows : ![E[err^2] = \sum_{i=1}^{N}\frac{(\overline{X}-X_i)^2}{N} = \sigma_P^2](https://s0.wp.com/latex.php?latex=E%5Berr%5E2%5D+%3D+%5Csum_%7Bi%3D1%7D%5E%7BN%7D%5Cfrac%7B%28%5Coverline%7BX%7D-X_i%29%5E2%7D%7BN%7D+%3D+%5Csigma_P%5E2&bg=ffffff&fg=333333&s=0&c=20201002)
We can see that the expected value of the error is nothing but the standard deviation of the population !
Standard Error when Sample Size = 2
Consider the case where the sample S consists of exactly two elements. Our aim is to find population mean. As per our approach, we pick two random elements 

We can derive the expected value for the error as ![E[err^2] = E[(\overline{X} - \overline{Y})^2] = Var[\overline{Y}]](https://s0.wp.com/latex.php?latex=E%5Berr%5E2%5D+%3D+E%5B%28%5Coverline%7BX%7D+-+%5Coverline%7BY%7D%29%5E2%5D+%3D+Var%5B%5Coverline%7BY%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![Var[\overline{Y}] = Var [\frac{Y_1 + Y_2}{2}] = Var [\frac{Y_1}{2} + \frac{Y_2}{2}] = \frac{1}{4} Var[Y_1] + \frac{1}{4} Var[Y_2] = \frac{\sigma_P^2}{4} + \frac{\sigma_P^2}{4} = \frac{\sigma_P^2}{2}](https://s0.wp.com/latex.php?latex=Var%5B%5Coverline%7BY%7D%5D+%3D+Var+%5B%5Cfrac%7BY_1+%2B+Y_2%7D%7B2%7D%5D+%3D+Var+%5B%5Cfrac%7BY_1%7D%7B2%7D+%2B+%5Cfrac%7BY_2%7D%7B2%7D%5D+%3D+%5Cfrac%7B1%7D%7B4%7D+Var%5BY_1%5D+%2B+%5Cfrac%7B1%7D%7B4%7D+Var%5BY_2%5D+%3D+%5Cfrac%7B%5Csigma_P%5E2%7D%7B4%7D+%2B+%5Cfrac%7B%5Csigma_P%5E2%7D%7B4%7D+%3D+%5Cfrac%7B%5Csigma_P%5E2%7D%7B2%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Note that we used rules 3, 6 and 7 from above.
Standard Error when Sample Size = n
We will not derive the formula here but we can easily show that when the sample contains n different elements the standard error is given by ![E[err^2] = \frac{\sigma_P^2}{n} = \frac{Variance\;of\;population}{Sample\;size}](https://s0.wp.com/latex.php?latex=E%5Berr%5E2%5D+%3D+%5Cfrac%7B%5Csigma_P%5E2%7D%7Bn%7D+%3D+%5Cfrac%7BVariance%5C%3Bof%5C%3Bpopulation%7D%7BSample%5C%3Bsize%7D&bg=ffffff&fg=333333&s=0&c=20201002)
There are some interesting things to note here :
1. The expected error when using 2 samples is less than that of the expected error when we used only one sample.
2. As the size of sample increases the error decreases even faster. The rate of decrease is inversely proportional to square of size of the sample size.
3. This also formalizes the intuition that if the variance of the population is less, we need less number of samples to provide estimates with small error.
4. Usually our work will dictate the tolerable error and we can use the formula to find the appropriate n that will make standard error less than our tolerance factor.
Hope this post was useful 🙂

