The title of this post is very similar to my old berkeley ML lectures post. Machine Learning is one of the coolest fields in CS and I really want to master it. But so far I was having trouble finding the basic intuitions behind the course. When I read the books, it somehow feels that I am missing some overarching intuition behind the field and that is the root cause behind all my troubles. I "think" I now know what it is. My math background is not as strong as I want to be. I have been putting lot of efforts over the last few months to rectify it. I have been poring over books on linear algebra, probability and statistics. I am still lacking a bit in Calculus but I am sure I will be making up soon.
I took two great courses this semester and they played a role in bridging the gap . They are Computational Methods and Bioinformatics. Both of them are taught by great teachers and had lot of fun topics. Computational Methods was an exploratory course discussing about lot of math needed for CS – things like root finding , linear and non linear equation solving, least squares, Eigen values , SVD and monte-carlo methods . As you can see it is a great sampling of techniques widely used in machine learning and other related fields (eg robotics, vision etc). The text books and other reference materials did a good job of pointing applications in machine learning. So I think I now appreciate many of the derivations used in machine learning better now. Similarly my bioinformatics course showed the various ways in which machine learning techniques are adapted to fit to that domain. As a combo they did a world of good to me.
Since I am now more confident, I started searching for Machine Learning lectures to restart my quest. There are lot of exceptional course websites and notes, but I preferred the courses with video/audio lectures. The most popular seems to be Stanford’s CS 229. It is great and has an excellent collection of notes. I have listened to few of the lectures before bailing out. Hopefully this time , I will be able to complete them. Since I already had (and partially listened to ) Berkeley lecutures, I was searching for similar courses in MIT to complete the triumvirate. I was surprised that OCW did not have a video lecture for data mining / machine learning. It is a pity as I feel these two fields are becoming very important in CS now. As I was systematically going through old courses , I hit a jackpot.
I found MIT’s 6.867 Machine Learning course taught by Professor Leslie Kaelbling in fall of 2005. They had video lectures but all their links were broken. I spent quite some time hunting for good sources and with some luck found them ! One of the things I liked about this course is this : It was taught in 2005 – Slightly old but not too old – and hence the course topics looks relatively approachable by my standards. Additionally the initial lectures discuss the necessary background which is an additional plus.
The archived course website is at 6.867 Machine Learning Fall 2005 . The video links are at SMA’s course website. Please note that the webpage explicitly states that it is copyrighted 😦 Hopefully they wont mind using it for academic purposes. Surprisingly the videos are again in rm format which I hate. One of the reasons is that it causes my Ubuntu based players to crash occasionally. The steps to download are a bit different from the one in Berkeley course. My instructions below are for ISO section. I downloaded a video from each and was not able to find any difference and the ISO files were smaller than the prog files. Also note that the URLs are provided in reverse chrological order. So the first link in the website corresponds to last lecture.
Download steps :
1. Find the url of the file. For eg the url of first lecture in ISO recording is http://smasvr.nus.edu.sg:8080/ramgen/sma/2005-2006/sma5514-fall/sma-5514-lec-mit-54100-07sep2005-0930-iso.rm .
2. Extract the rm file name from the url . Here it is sma-5514-lec-mit-54100-07sep2005-0930-iso.rm .
3. Construct the rtsp url. As of now, the rtsp url looks like this – rtsp://137.132.165.11:554/sma/2005-2006/sma5514-fall/lectFile . So for our case it is rtsp://137.132.165.11:554/sma/2005-2006/sma5514-fall/sma-5514-lec-mit-54100-07sep2005-0930-iso.rm .
4. Download the file using mplayer. The one that worked for me is this : mplayer -noframedrop -dumpfile Lect1.rm -dumpstream rtsp://137.132.165.11:554/sma/2005-2006/sma5514-fall/sma-5514-lec-mit-54100-07sep2005-0930-iso.rm . Remember to replace the arguments for dumpfile and dumpstream for each download.
5. Convert to other formats. Use mencoder to convert to other formats. For some reason, all the formats I tried resulted in very large files. If anyone found a way to convert it effectively, please let me know.
6. Enjoy the videos !
Other Notes
1. The files will download in a slow fashion. The reason is that mplayer will try to download them as if you are actually watching them. I tried to play with the caching by setting a large value for the bandwidth parameter but it did caused some premature termination. If anyone got it working please comment .
2. I was also not able to convert the rm files to other formats avi or mp4 correctly. The files were of 2-3 times the size of the original rm file. If anyone found the proper incantation please let me know.
I plan to listen to them in December and January. If I learn any cool ideas, I will blog about them. Have fun with the video lectures !
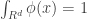
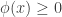

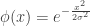

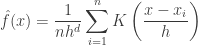

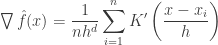
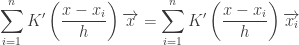
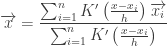
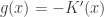 , we have
, we have
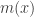 is called as the mean shift. So mean shift procedure can be summarized as : For each point
is called as the mean shift. So mean shift procedure can be summarized as : For each point 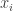
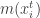
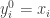
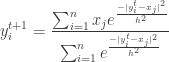
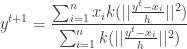
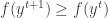

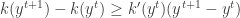

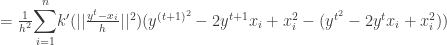
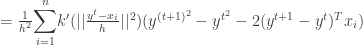
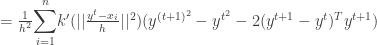


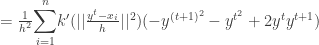
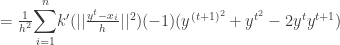

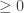
 is convergent. The second part of the proof in [2] which tries to prove the sequence
is convergent. The second part of the proof in [2] which tries to prove the sequence 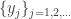 is convergent is wrong.
is convergent is wrong.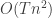 where
where  is the number of iterations and
is the number of iterations and  is the number of data points in the data set. Many improvements have been made to the mean shift algorithm to make it converge faster.
is the number of data points in the data set. Many improvements have been made to the mean shift algorithm to make it converge faster. parameter is calculated using kNN algorithm. If
parameter is calculated using kNN algorithm. If 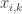 is the k-nearest neighbor of
is the k-nearest neighbor of 
 or
or  norm to find the bandwidth.
norm to find the bandwidth.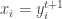
 where k is the number of clusters, n is the number of points and T is the number of iterations. Classic mean shift is computationally expensive with a time complexity
where k is the number of clusters, n is the number of points and T is the number of iterations. Classic mean shift is computationally expensive with a time complexity 






