In this post, I plan to discuss about two very simple inequalities – Markov and Chebyshev. These are topics that are covered in any elementary probability course. In this post, I plan to give some intuitive explanation about them and also try to show them in different perspectives. Also, the following discussion is closer to discrete random variables even though most of them can be extended to continuous ones.
Inequalities from an Adversarial Perspective
One interesting way of looking at the inequalities is from an adversarial perspective. The adversary has given you some limited information and you are expected to come up with some bound on the probability of an event. For eg, in the case of Markov inequality, all you know is that the random variable is non negative and its (finite) expected value. Based on this information, Markov inequality allows you to provide some bound on the tail inequalities. Similarly, in the case of Chebyshev inequality, you know that the random variable has a finite expected value and variance. Armed with this information Chebyshev inequality allows you to provide some bound on the tail inequalities. The most fascinating this about these inequalities is that you do not have to know the probabilistic mass function(pmf). For any arbitrary pmf satisfying some mild conditions, Markov and Chebyshev inequalities allow you to make intelligent guesses about the tail probability.
A Tail Inequality perspective
Another way of looking at these inequalities is this. Supposed we do not know anything about the pmf of a random variable and we are forced to make some prediction about the value it takes. If the expected value is known, a reasonable strategy is to use it. But then the actual value might deviate from our prediction. Markov and Chebyshev inequalities are very useful tools that allow us to estimate how likely or unlikely that the actual value varies from our prediction. For eg, we can use Markov inequality to bound the probability that the actual varies by some multiple of the expected value from the mean. Similarly, using Chebyshev we can bound the probability that the difference from mean is some multiple of its standard deviation.
One thing to notice is that you really do not need the pmf of the random variable to bound the probability of the deviations. Both these inequalities allow you to make deterministic statements of probabilistic bounds without knowing much about the pmf.
Markov Inequality
Let us first take a look at the Markov Inequality. Even though the statement looks very simple, clever application of the inequality is at the heart of more powerful inequalities like Chebyshev or Chernoff. Initially, we will see the simplest version of the inequality and then we will discuss the more general version. The basic Markov inequality states that given a random variable X that can only take non negative values, then
![Pr(X \geq k E[X]) \leq \frac{1}{k}](https://s0.wp.com/latex.php?latex=Pr%28X+%5Cgeq+k+E%5BX%5D%29+%5Cleq+%5Cfrac%7B1%7D%7Bk%7D&bg=ffffff&fg=333333&s=0&c=20201002)
There are some basic things to note here. First the term P(X >= k E(X)) estimates the probability that the random variable will take the value that exceeds k times the expected value. The term P(X >= E(X)) is related to the cumulative density function as 1 – P(X < E(X)). Since the variable is non negative, this estimates the deviation on one side of the error.
Intuitive Explanation of Markov Inequality
Intuitively, what this means is that , given a non negative random variable and its expected value E(X)
(1) The probability that X takes a value that is greater than twice the expected value is atmost half. In other words, if you consider the pmf curve, the area under the curve for values that are beyond 2*E(X) is atmost half.
(2) The probability that X takes a value that is greater than thrice the expected value is atmost one third.
and so on.
Let us see why that makes sense. Let X be a random variable corresponding to the scores of 100 students in an exam. The variable is clearly non negative as the lowest score is 0. Tentatively lets assume the highest value is 100 (even though we will not need it). Let us see how we can derive the bounds given by Markov inequality in this scenario. Let us also assume that the average score is 20 (must be a lousy class!). By definition, we know that the combined score of all students is 2000 (20*100).
Let us take the first claim – The probability that X takes a value that is greater than twice the expected value is atmost half. In this example, it means the fraction of students who have score greater than 40 (2*20) is atmost 0.5. In other words atmost 50 students could have scored 40 or more. It is very clear that it must be the case. If 50 students got exactly 40 and the remaining students all got 0, then the average of the whole class is 20. Now , if even one additional student got a score greater than 40, then the total score of 100 students become 2040 and the average becomes 20.4 which is a contradiction to our original information. Note that the scores of other students that we assumed to be 0 is an over simplification and we can do without that. For eg, we can argue that if 50 students got 40 then the total score is atleast 2000 and hence the mean is atleast 20.
We can also see how the second claim is true. The probability that X takes a value that is greater than thrice the expected value is atmost one third. If 33.3 students got 60 and others got 0 , then we get the total score as around 2000 and the average remains the same. Similarly, regardless of the scores of other 66.6 students, we know that the mean is atleast 20 now.
This also must have made clear why the variable must be non negative. If some of the values are negative, then we cannot claim that mean is atleast some constant C. The values that do not exceed the threshold may well be negative and hence can pull the mean below the estimated value.
Let us look at it from the other perspective : Let p be the fraction of students who have a score of atleast a . Then it is very clear to us that the mean is atleast a*p. What Markov inequality does is to turn this around. It says, if the mean is a*p then the fraction of students with a score greater than a is atmost p. That is, we know the mean here and hence use the threshold to estimate the fraction .
Generalized Markov Inequality
The probability that the random variable takes a value thats greater than k*E(X) is at most 1/k. The fraction 1/k act as some kind of a limit. Taking this further, you can observe that given an arbitrary constant a, the probability that the random variable X takes a value >= a ie P(X >= a) is atmost 1/a times the expected value. This gives the general version of Markov inequality.
![Pr(X \geq a) \leq \frac{1}{a} E[X]](https://s0.wp.com/latex.php?latex=Pr%28X+%5Cgeq+a%29+%5Cleq+%5Cfrac%7B1%7D%7Ba%7D+E%5BX%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
In the equation above, I seperated the fraction 1/a because that is the only varying part. We will later see that for Chebyshev we get a similar fraction. The proof of this inequality is straightforward. There are multiple proofs even though we will use the follow proof as it allows us to show Markov inequality graphically.This proof is partly taken from Mitzenmacher and Upfal’s exceptional book on Randomized Algorithms.
Consider a constant a >= 0. Then define an indicator random variable I which takes value of 1 is X >=a . ie

Now we make a clever observation. We know that X is non negative. ie X >= 0. This means that the fraction X/a is atleast 0 and atmost can be infinty. Also, if X < a, then X/a < 1. When X > a, X/a > 1. Using these facts,

If we take expectation on both sides, we get
![E[I] \leq \frac{1}{a} E[X]](https://s0.wp.com/latex.php?latex=E%5BI%5D+%5Cleq+%5Cfrac%7B1%7D%7Ba%7D+E%5BX%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
But we also know that the expectation of indicator random variable is also the probability that it takes the value 1. This means E[I] = Pr(X>=a). Putting it all together, we get the Markov inequality.
Even more generalized Markov Inequality
Sometimes, it might happen that the random variable is not non-negative. In cases like this, a clever hack helps. Design a function f(x) such that f(x) is non negative. Then we can apply Markov inequality on the modified random variable f(X). The Markov inequality for this special case is :
![Pr(f(X) \geq a) \leq \frac{1}{a} E[f(X)]](https://s0.wp.com/latex.php?latex=Pr%28f%28X%29+%5Cgeq+a%29+%5Cleq+%5Cfrac%7B1%7D%7Ba%7D+E%5Bf%28X%29%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
This is a very powerful technique. Careful selection of f(X) allows you to derive more powerful bounds.
(1) One of the simplest examples is f(X) = |X| which guarantees f(X) to be non negative.
(2) Later we will show that Chebyshev inequality is nothing but Markov inequality that uses
(3) Under some additional constraints, Chernoff inequality uses 

Simple Examples
Let us consider a simple example where it provides a decent bound and one where it does not. A typical example where Markov inequality works well is when the expected value is small but the threshold to test is very large.
Example 1:
Consider a coin that comes up with head with probability 0.2 . Let us toss it n times. Now we can use Markov inequality to bound the probability that we got atleast 80% of heads.
Let X be the random variable indicating the number of heads we got in n tosses. Clearly, X is non negative. Using linearity of expectation, we know that E[X] is 0.2n.We want to bound the probability P(X >= 0.8n). Using Markov inequality , we get

Of course we can estimate a finer value using the Binomial distribution, but the core idea here is that we do not need to know it !
Example 2:
For an example where Markov inequality gives a bad result, let us the example of a dice. Let X be the face that shows up when we toss it. We know that E[X] is 7/2 = 3.5. Now lets say we want to find the probability that X >= 5. By Markov inequality,

The actual answer of course is 2/6 and the answer is quite off. This becomes even more bizarre , for example, if we find P(X >= 3) . By Markov inequality,

The upper bound is greater than 1 ! Of course using axioms of probability, we can set it to 1 while the actual probability is closer to 0.66 . You can play around with the coin example or the score example to find cases where Markov inequality provides really weak results.
Tightness of Markov
The last example might have made you think that the Markov inequality is useless. On the contrary, it provided a weak bound because the amount of information we provided to it is limited. All we provided to it were that the variable is non negative and that the expected value is known and finite. In this section, we will show that it is indeed tight – that is Markov inequality is already doing as much as it can.
From the previous example, we can see an example where Markov inequality is tight. If the mean of 100 students is 20 and if 50 students got a score of exactly 0, then Markov implies that atmost 50 students can get a score of atleast 40.
Note : I am not 100% sure if the following argument is fully valid – But atleast it seems to me 🙂
Consider a random variable X such that

We can estimate its expected value as
![E[X] = \frac{1}{k} \times k + \frac{k-1}{k} \times 0 = 1](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Cfrac%7B1%7D%7Bk%7D+%5Ctimes+k+%2B+%5Cfrac%7Bk-1%7D%7Bk%7D+%5Ctimes+0+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002)
We can see that ,
![Pr(X \geq k E[X]) = Pr(X \geq k) = \frac{1}{k}](https://s0.wp.com/latex.php?latex=Pr%28X+%5Cgeq+k+E%5BX%5D%29+%3D+Pr%28X+%5Cgeq+k%29+%3D+%5Cfrac%7B1%7D%7Bk%7D+&bg=ffffff&fg=333333&s=0&c=20201002)
This implies that the bound is actually tight ! Of course one of the reasons why it was tight is that the other value is 0 and the value of the random variable is exactly k. This is consistent with the score example we saw above.
Chebyshev Inequality
Chebyshev inequality is another powerful tool that we can use. In this inequality, we remove the restriction that the random variable has to be non negative. As a price, we now need to know additional information about the variable – (finite) expected value and (finite) variance. In contrast to Markov, Chebyshev allows you to estimate the deviation of the random variable from its mean. A common use of it estimates the probability of the deviation from its mean in terms of its standard deviation.
Similar to Markov inequality, we can state two variants of Chebyshev. Let us first take a look at the simplest version. Given a random variable X and its finite mean and variance, we can bound the deviation as
![P(|X-E[X]| \geq k \sigma ) \leq \frac{1}{k^2}](https://s0.wp.com/latex.php?latex=P%28%7CX-E%5BX%5D%7C+%5Cgeq+k+%5Csigma+%29+%5Cleq+%5Cfrac%7B1%7D%7Bk%5E2%7D&bg=ffffff&fg=333333&s=0&c=20201002)
There are few interesting things to observe here :
(1) In contrast to Markov inequality, Chebyshev inequality allows you to bound the deviation on both sides of the mean.
(2) The length of the deviation is 
(3) Intuitively, if the variance of X is small, then Chebyshev inequality tells us that X is close to its expected value with high probability.
(4) Using Chebyshev inequality, we can claim that atmost one fourth of the values that X can take is beyond 2 standard deviation of the mean.
Generalized Chebyshev Inequality
A more general Chebyshev inequality bounds the deviation from mean to any constant a . Given a positive constant a ,
![Pr(|X-E[X]| \geq a) \leq \frac{1}{a^2}\;Var[X]](https://s0.wp.com/latex.php?latex=Pr%28%7CX-E%5BX%5D%7C+%5Cgeq+a%29+%5Cleq+%5Cfrac%7B1%7D%7Ba%5E2%7D%5C%3BVar%5BX%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Proof of Chebyshev Inequality
The proof of this inequality is straightforward and comes from a clever application of Markov inequality. As discussed above we select ![f(x) = |X-E[X]|^2](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%7CX-E%5BX%5D%7C%5E2&bg=ffffff&fg=333333&s=0&c=20201002)
![Pr(|X-E[X]| \geq a) = Pr( (X-E[X])^2 \geq a^2)](https://s0.wp.com/latex.php?latex=Pr%28%7CX-E%5BX%5D%7C+%5Cgeq+a%29+%3D+Pr%28+%28X-E%5BX%5D%29%5E2+%5Cgeq+a%5E2%29&bg=ffffff&fg=333333&s=0&c=20201002)
![Pr( (X-E[X])^2 \geq a^2) \leq \frac{1}{a^2} E[(X-E[X])^2]](https://s0.wp.com/latex.php?latex=Pr%28+%28X-E%5BX%5D%29%5E2+%5Cgeq+a%5E2%29+%5Cleq+%5Cfrac%7B1%7D%7Ba%5E2%7D+E%5B%28X-E%5BX%5D%29%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
We used the Markov inequality in the second line and used the fact that ![Var[X] = E[(X-E[X])^2]](https://s0.wp.com/latex.php?latex=Var%5BX%5D+%3D+E%5B%28X-E%5BX%5D%29%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Common Pitfalls
It is important to notice that Chebyshev provides bound on both sides of the error. One common mistake to do when applying Chebyshev is to divide the resulting probabilistic bound by 2 to get one sided error. This is valid only if the distribution is symmetric. Else it will give incorrect results. You can refer Wikipedia to see one sided Chebyshev inequalities.
Chebyshev Inequality for higher moments
One of the neat applications of Chebyshev inequality is to use it for higher moments. As you would have observed, in Markov inequality, we used only the first moment. In the Chebyshev inequality, we use the second moment (and first). We can use the proof above to adapt Chebyshev inequality for higher moments. In this post, I will give a simple argument for even moments only. For general argument (odd and even) look at this Math Overflow post.
The proof of Chebyshev for higher moments is almost exactly the same as the one above. The only observation we make is that ![(X-E[X])^{2k}](https://s0.wp.com/latex.php?latex=%28X-E%5BX%5D%29%5E%7B2k%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![E[(X-E[X])^{2k}](https://s0.wp.com/latex.php?latex=E%5B%28X-E%5BX%5D%29%5E%7B2k%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![Pr(|X-E[X]| > t \sqrt[2k] {E[(X-E[X])^{2k}]}) \leq \frac{1}{t^{2k}}](https://s0.wp.com/latex.php?latex=Pr%28%7CX-E%5BX%5D%7C+%3E+t+%5Csqrt%5B2k%5D+%7BE%5B%28X-E%5BX%5D%29%5E%7B2k%7D%5D%7D%29+%5Cleq+%5Cfrac%7B1%7D%7Bt%5E%7B2k%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
It should be intuitive to note that the more information we get the tighter the bound is. For Markov we got 1/t as the fraction. It was 1/a^2 for second order Chebyshev and 1/a^k for k^th order Chebyshev inequality.
Chebyshev Inequality and Confidence Interval
Using Chebyshev inequality, we previously claimed that atmost one fourth of the values that X can take is beyond 2 standard deviation of the mean. It is possible to turn this statement around to get a confidence interval.
If atmost 25% of the population are beyond 2 standard deviations away from mean, then we can be confident that atleast 75% of the population lie in the interval ![(E[X]-2 \sigma, E[X]+2 \sigma)](https://s0.wp.com/latex.php?latex=%28E%5BX%5D-2+%5Csigma%2C+E%5BX%5D%2B2+%5Csigma%29&bg=ffffff&fg=333333&s=0&c=20201002)

![(E[X]-k. \sigma, E[X]+k \sigma)](https://s0.wp.com/latex.php?latex=%28E%5BX%5D-k.+%5Csigma%2C+E%5BX%5D%2Bk+%5Csigma%29&bg=ffffff&fg=333333&s=0&c=20201002)
Applications of Chebyshev Inequality
We previously saw two applications of Chebyshev inequality – One to get tighter bounds using higher moments without using complex inequalities. The other is to estimate confidence interval. There are some other cool applications that we will state without providing the proof. For proofs refer the Wikipedia entry on Chebyshev inequality.
(1) Using Chebyshev inequality, we can prove that the median is atmost one standard deviation away from the mean.
(2) Chebyshev inequality also provides the simplest proof for weak law of large numbers.
Tightness of Chebyshev Inequality
Similar to Markov inequality, we can prove the tightness of Chebyshev inequality. I had fun deriving this proof and hopefully some one will find it useful. Define a random variable X as ,
[Note: I could not make the case statement work in WordPress Latex and hence the crude work around]
X = { 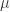
{
{
![E[X] = p(\mu +C) + p(\mu -C) + (1-2p) \mu = \mu](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+p%28%5Cmu+%2BC%29+%2B+p%28%5Cmu+-C%29+%2B+%281-2p%29+%5Cmu+%3D+%5Cmu+&bg=ffffff&fg=333333&s=0&c=20201002)
![Var[X] = E[(X-\mu)^2]](https://s0.wp.com/latex.php?latex=Var%5BX%5D+%3D+E%5B%28X-%5Cmu%29%5E2%5D+&bg=ffffff&fg=333333&s=0&c=20201002)

![\Rightarrow Var[X] = 2pC^2](https://s0.wp.com/latex.php?latex=%5CRightarrow+Var%5BX%5D+%3D+2pC%5E2&bg=ffffff&fg=333333&s=0&c=20201002)
If we want to find the probability that the variable deviates from mean by constant C, the bound provided by Chebyshev is ,
![Pr(|X-\mu| \geq C) \leq \frac{Var[X]}{C^2} = \frac{2pC^2}{C^2}=2p](https://s0.wp.com/latex.php?latex=Pr%28%7CX-%5Cmu%7C+%5Cgeq+C%29+%5Cleq+%5Cfrac%7BVar%5BX%5D%7D%7BC%5E2%7D+%3D+%5Cfrac%7B2pC%5E2%7D%7BC%5E2%7D%3D2p&bg=ffffff&fg=333333&s=0&c=20201002)
which is tight !
Conclusion
Markov and Chebyshev inequalities are two of the simplest , yet very powerful inequalities. Clever application of them provide very useful bounds without knowing anything about the distribution of the random variable. Markov inequality bounds the probability that a nonnegative random variable exceeds any multiple of its expected value (or any constant). Chebyshev’s inequality , on the other hand, bounds the probability that a random variable deviates from its expected value by any multiple of its standard deviation. Chebyshev does not expect the variable to non negative but needs additional information to provide a tighter bound. Both Markov and Chebyshev inequalities are tight – This means with the information provided, the inequalities provide the most information they can provide.
Hope this post was useful ! Let me know if there is any insight I had missed !
References
(1) Probability and Computing by Mitzenmacher and Upfal.
(2) An interactive lesson plan on Markov’s inequality – An extremely good discussion on how to teach Markov inequality to students.
(3) This lecture note from Stanford – Treats the inequalities from a prediction perspective.
(4) Found this interesting link from Berkeley recently.

