Author Note : My blog is getting the first guest post ! This post is written by dear friend and fellow geek Kripa who just graduated from Columbia University. He specializes in Machine Learning, NLP and Data Mining. Over the last few months, he has been doing some amazing exploratory work in Data Mining. This blog post describes one such work. Here he describes how he applied LDA on movie scripts to determine the mixture of genres. Aside from being a cool application of LDA, finding such genre mixture has multiple applications. For eg, this can provide a mechanism to improve movie recommendations. You can even use it to deconstruct the work of your favorite artist !
Every movie predominantly falls into a particular genre that can be one of war, crime, adventure, thriller, comedy, romance, etc. Sometimes there is more than one genre a movie can belong to. For example a movie like Minority Report though predominantly belongs to sci-fi has very strong elements of crime in the storyline. Given a movie, I wanted to look at some approximate percentages of genres contained in it.
If I throw a movie like Pearl Harbor at my system, I expect it to return an output like:
war: 35%
crime: 13%
comedy: 13%
horror: 9%
romance: 19%
sci-fi: 11%
I decided to consider only these six genres as others like Adventure, Action, Thriller, etc are mostly overlaps. For example, action is a broad category – war and crime could also be considered action; and a thriller could be a medley of action and crime. For my experiment I considered only those genres which I felt were distinct from each other.
Data
The first question is what kind of data to go after? Movie plots are available from the IMDB dataset. They do express the major genre well but they don’t contain a lot of information to get the minor genres out. Wikipedia usually contains a detailed plot, but I found something better: Internet Movie Script Database (imsdb here forth). This is an online repository of movie scripts which contain dialogues and also contextual scene information.
For example consider this scene from The Patriot:
Marion leaves the workshop with Susan at his side. Nathan and Samuel walk past, exhausted from their day in the field.
NATHAN: Father, I saw a post rider at the house.
MARION: Thank you. Did you finish the upper field?
SAMUEL: We got it all cut and we bundled half of it.
MARION: Those swimming breaks cut into the day, don’t they?
This contains both the dialogues and the description of the scene. It struck me as the right kind of data I should be looking at. Also this had a good amount of scripts (~1000 movies) for running a quick experiment. I did a quick and dirty wget of all the webpages followed by a bunch of shell scripts to weed out html tags and expressions such as "CAMERA PANS OUT" and "SCENE SHIFTS TO" that add no information to the script. I also removed the stop words and proper nouns. After pre-processing I had just the text of dialogues and the scene description.
Now that I have data, how did I go about finding the composition of genres in a movie?
Supervised vs Unsupervised
Let us define the problem elaborately. I have the pre-processed imsdb content which is the data and its genre is its label. A simple classification task will involve extracting features from the labeled data and training it using a classifier to build a model. This model can then be used to predict the genre of a movie that is out of the training data. This is a supervised approach where we already have the labeled data – genre of a movie. For my task of detecting a mixture of genres, all I would need to do is to tweak the classifier output so that it gives the individual probabilities of each genre a movie can possibly belong to. But is this the right approach? Will the output probabilities be close to the actual representation of genres in a movie?
There are couple of issues with this supervised approach.
My expectation from an unsupervised approach is simple. I have a huge collection of unlabeled scripts. I’m assuming that each script contains a mixture of genres.
I now need to extract features (words) that are relevant to each genre from this corpus. In better words, given a corpus of scripts, the unsupervised system needs to discover from the corpus a bunch of topics and list the most relevant features (words) that belong to each topic. I would then be able to use the features to infer the topic mixture of each individual script. This is known as Topic Modelling . Intuitively I’m trying to generate a bag of words model out of a corpus of scripts.
Latent Dirichlet Allocation
LDA is a topic model and one which is most widely used today. I will not spend much effort in giving a rigorous treatment on LDA since there are excellent resources available online. I’m listing those that I found extremely useful for understanding LDA.
-
You can find Prof.Blei’s implementation of LDA in C on his webpage.
-
Edwin Chen’s blog article is one of the best sources for grasping the intuition behind LDA even if you are mathematically less inclined.
A word of warning here! I will write a brief note about my understanding of LDA. Honestly, there are better ways of explaining LDA. At this point all you need know is that LDA is a statistical black box – throw a bunch of documents at it; specify ‘k’ – the number of topics you think are represented by the documents and LDA will output ‘k’ topic vectors. Each topic vector contains words arranged in decreasing probabilities of being associated with that particular topic. You need to know ONLY THIS! So feel free to skip to the next section.
In the case of Maximum Likelihood given n data points, we assume the underlying distribution that generated this data is a Gaussian and fit the data to the best Gaussian possible. LDA also makes a similar assumption that there is a hidden structure to the data. And that hidden structure is a multinomial whose parameter 
Let us say that I want to generate a random document; I don’t care if its meaningful or not. I first fix the number of words I would want to generate in that document. I can on the other hand draw a random number from say a Poisson. Once I have the number of words (N) to be generated, I go ahead to generate those many words from the corpus.
Each word is generated thus: draw a 

So I have an 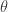
Remember that I’m trying to generate a random document and I haven’t generated a single word yet! The
Now that
I have not yet generated a word! To generate a word that belongs to a topic, I need a |V| faced die. |V| is the size of the vocabulary of the corpus. How do I get such a huge die?!
I will get that in a similar way as for the topic vector. I will sample again from a Dirichlet – but a different Dirichlet – one that is over a v-dimensional simplex. Any draw from this Dirichlet will give a v-faced die. Call this the Dirichlet 
So for topic-5, I throw the 5th v-faced die. Let us say it shows 42; I then go to the vocabulary and pick the 42nd word! I will do this whole process ‘N’ times (N was the number of words to be generated for the random document.)
The crux of this discussion is this: for every document , the dice (i.e samples from the dirichlet(
Running LDA on Movie Scripts
I converted the imsdb data to a format accepted by Prof. Blei’s code. For more information you should look at his README. I initially ran the code with k = 10 (guessing that the movie scripts could represent a mixture of 10 genres). I will jump from here to give a sneak peek at the end results. The end results have been very encouraging. A sample of words clustered under different topics is here:

At this point eyeballing the clusters it is apparent that the starting from the red cloud, clockwise, the clusters represent romance, sci-fi, war, horror, comedy and crime respectively.
Just running LDA on the data with k=10 did not turn out such relevant results. So what was that extra mile which had to be crossed?
LDA does not always guarantee relevant features. Nor is every topic discovered meaningful. After the first run, by eyeballing through the 10 topics, I was able to distinguish 3 topics very easily – war, romance and sci-fi. Playing around with different ‘k’ values did not yield more discernible topics. There are reasons to this:
I removed the scripts corresponding to war and sci-fi from the dataset. This was achieved by comparing each script in the dataset against the top features from these topics. Each script was scored based on the occurance of features. I removed the scripts that scored greater than a threshold. The new dataset D* contained scripts other than war and science fiction movies. Then I ran LDA on this new dataset D*. Now I found that the topics pertaining to crime and comedy were getting discovered but their features were mangled with romance. This feature set was improved by removing words which were common to most categories and were not exclusive to one particular category.
This paper deals with using human judgments to examine topics. This is one way of picking the odd feature out of a topic vector. The final feature set looked something like this.
Results
I wrote a simple python script that does soft-clustering based on occurance and count of features. A sample of the results is here:

The results were quite convincing to look at. I wanted to obtain some hard metrics. IMSDB already categorises movies based on its genre. So I consider the category as the actual label. A movie is considered to be rightly classified if the label matches one of the top two genres detected by my system. The following are some encouraging results!

These proportions cannot be considered accurate, but they do give an idea of what to expect from a movie! The complete list of results is here .
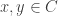 and any
and any ![\alpha \in [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,
 is a convex set. One of the interesting properties of such sets is that the intersection of two convex sets is again a convex set. We will exploit this feature when discussing the geometric interpretation of Linear Programming.
is a convex set. One of the interesting properties of such sets is that the intersection of two convex sets is again a convex set. We will exploit this feature when discussing the geometric interpretation of Linear Programming. , and
, and 




 which also satisfies the constraints is called as a feasible solution. The challenge in Linear Programming is to select a feasible solution that maximizes the objective function. Of course, real world linear programming instances might have different inequalities – for eg
which also satisfies the constraints is called as a feasible solution. The challenge in Linear Programming is to select a feasible solution that maximizes the objective function. Of course, real world linear programming instances might have different inequalities – for eg 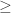 instead of
instead of  or the value of
or the value of  is bound between
is bound between ![[p_i , q_i]](https://s0.wp.com/latex.php?latex=%5Bp_i+%2C+q_i%5D&bg=ffffff&fg=333333&s=0&c=20201002) . But in almost all such cases, we can convert that linear programming instance to the standard form in a finite time. For the rest of the lecture, we will focus on linear programming problems in standard form as this simplifies the exposition.
. But in almost all such cases, we can convert that linear programming instance to the standard form in a finite time. For the rest of the lecture, we will focus on linear programming problems in standard form as this simplifies the exposition.
 represents the objective function.
represents the objective function. 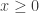 represent the non negativity constraints. A is matrix of dimensions
represent the non negativity constraints. A is matrix of dimensions 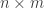 and each of its row represents an inequality. Each of the column represent a variable. So the inequality
and each of its row represents an inequality. Each of the column represent a variable. So the inequality  becomes the
becomes the  row of whose elements are
row of whose elements are  . The column vector b represents the RHS of each inequality and the
. The column vector b represents the RHS of each inequality and the  .
.

 divides the plane into two regions: the set of points(x1,x2) such that
divides the plane into two regions: the set of points(x1,x2) such that  which are not feasible for our problem and the points such that
which are not feasible for our problem and the points such that  where the inequality is satisfied. The first set does not contain any feasible solution but the second set could contain points which are feasible solution of the problem provided they also satisfy the other inequalities. The line equation
where the inequality is satisfied. The first set does not contain any feasible solution but the second set could contain points which are feasible solution of the problem provided they also satisfy the other inequalities. The line equation  is the boundary which separates these regions. In the figure below, the shaded region contains the set of points which satisfy the inequality.
is the boundary which separates these regions. In the figure below, the shaded region contains the set of points which satisfy the inequality.

 forms the boundary for constraint
forms the boundary for constraint 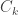 . The feasible region formed by intersection of all the constraint hyperplane is a polytope.
. The feasible region formed by intersection of all the constraint hyperplane is a polytope.
 and $2x_1+x_2 \leq 1$ to equalities and solving for them. So in a two variable linear programming instance with m constraints, there can atmost be
and $2x_1+x_2 \leq 1$ to equalities and solving for them. So in a two variable linear programming instance with m constraints, there can atmost be  vertices. This results in a simple brute force algorithm (assuming the problem is feasible):
vertices. This results in a simple brute force algorithm (assuming the problem is feasible):
 potential vertices and the naive algorithm takes around
potential vertices and the naive algorithm takes around  and results in an exponential time algorithm.
and results in an exponential time algorithm. . There are potentially, n neighbors for V. To find each of them , we can set equation
. There are potentially, n neighbors for V. To find each of them , we can set equation  back to inequality (other equations are unaltered) and find the set of feasible points for the new system (with n-1 equations and rest inequalities).
back to inequality (other equations are unaltered) and find the set of feasible points for the new system (with n-1 equations and rest inequalities). exists whose cost is greater than V, set
exists whose cost is greater than V, set  and repeat step 2.
and repeat step 2. . The cost of this point is 0. So we do not need to check any points with cost of below 0. The figure below shows the feasible region we must still explore and the line
. The cost of this point is 0. So we do not need to check any points with cost of below 0. The figure below shows the feasible region we must still explore and the line  which is our initial stab at pruning the region.
which is our initial stab at pruning the region.
 and including the equation
and including the equation  . Similarly, we can obtain the point (0,0.5) by discarding the equation
. Similarly, we can obtain the point (0,0.5) by discarding the equation 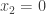 and including the equation
and including the equation  . Both of the vertices have same cost of 0.5 and lets arbitrarily pick the vertex (0.5,0). So the new lower bound of the objective function becomes 0.5 and we do not need to check any more points in the region where
. Both of the vertices have same cost of 0.5 and lets arbitrarily pick the vertex (0.5,0). So the new lower bound of the objective function becomes 0.5 and we do not need to check any more points in the region where  . The figure below shows the new region to explore.
. The figure below shows the new region to explore.
 . When we try to find the feasible region where
. When we try to find the feasible region where  we do not find any and we output this point as the optimum. The figure below shows the final result.
we do not find any and we output this point as the optimum. The figure below shows the final result.
 .
. where L informally, is the number of bits of input to the algorithm. The high cost of ellipsoid algorithm is attributable to the cutting plane oracle which says how the ellipsoid must be cut to form half-ellipsoids and also constructing a minimal volume ellipsoid over the half-ellipsoid that contains the optimal point.
where L informally, is the number of bits of input to the algorithm. The high cost of ellipsoid algorithm is attributable to the cutting plane oracle which says how the ellipsoid must be cut to form half-ellipsoids and also constructing a minimal volume ellipsoid over the half-ellipsoid that contains the optimal point.
 for some constant in C. Since we can verify the certificate in polynomial time, Linear programming is in
for some constant in C. Since we can verify the certificate in polynomial time, Linear programming is in  .
.
