This series of posts discusses some basic ideas in data mining . For all posts in the series see here.
I got lot of useful feedback on my post on K-means. Most common were to discuss the basic intuition in more detail and to include more figures to clarify the ideas . Thanks people for those comments !
Topic and Organization
In this post , I will discuss about Principal Component Analysis aka PCA , a very popular dimensionality reduction technique. It has an amazing variety of applications in statistics, data mining, machine learning, image processing etc
PCA is a huge topic to cover in a single post. So I plan to write it as a trilogy – First post will talk about PCA in lower dimensions with emphasis on geometric intuition and application to compression. Second post will extend it to arbitrary dimensions and discuss about basic dimensionality reduction , and the two common algorithms for calculating PCA. Third post will discuss Eigenfaces , which is probably one of the coolest application of PCA where we use it for face recognition.
Motivation for PCA
Before discussing PCA per se, let us discuss the reasons why PCA is one of the most important technique in data mining / machine learning. In this post I will primarily discuss with respect to compression. In the next post, we will discuss the more general idea of dimensionality reduction.
Let us assume that we have some arbitrary process that generates (x,y) points in 2 dimensional space . We do not know the behavior/internals of the process but we suspect that there is some inherent relation between x and y. There can be many reasons for trying to know the internal behavior. For eg if we know the relation between x and y, then we need to store only x and the transformation function. For eg if we had 1000 points in 2 dimensions , then we need 2000 words to store them (assuming each number takes word to store ,which is 4 bytes) . But if we knew the relation between x and y, we only need to store 1000 numbers (ie only x) which will occupy 1000 words as we can recalculate y from x using the transformation function. We get a 50% compression !
Let us take an example. Assume that our unknown process, generated some points which when plotted , we get the following graph. 
The red lines are the x-y axes and the green crosses are the points generated by the process. The relation between x and y is obvious to us now. The internal logic is 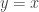

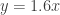


Let us discuss the
Short Detour To Linear Algebra : Vector Spaces and Basis
Basis is one of the fundamental ideas in Linear Algebra. I will give a short discussion of basis here – for more details consult some good book on Linear Algebra or some video lectures on it. For more details on learning it see my post on Linear Algebra .
Before discussing basis, let us talk about Vector Spaces. Intuitively, a vector space is a collection of vectors . It has the additional property that if you take any two vectors in it and add them, the result is also in the original collection. Similarly, if you multiply any vector by a scalar , the result is also in the original collection. So we can say that vector space is a collection of vectors that are "closed" under vector addition and scalar multiplication. A subspace is a similar idea. A subspace is subset of vectors in the original vector space but also have the behavior of a vector space. ie being closed under vector operations.
If the above paragraph sounded very abstract , it isn’t. You can consider the set of all real values vectors representing points in 2 dimensions as vector space. It is represented as 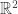
Now that we have discussed vector spaces, let us talk about Basis. Basis is again a set of vectors. We say that B is a Basis for a Vector Space V , if all the vectors in vector space V can be expressed as a linear combination of the vectors in the basis,B . So the vectors in the basis can express every vector in the vector space as a linear combination of themselves but no vector in a basis can be expressed as linear combination of other vectors in a basis. Wikipedia concisely states this fact – Basis is a "linearly independent spanning set."
The idea of Basis might sound confusing, but an example might clear it. Let us consider all the real valued 2-dimensional points represented by
![e_1=\left[ \begin{array}{c} 1 \\ 0 \end{array} \right] , e_2=\left[ \begin{array}{c} 0 \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=e_1%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+%2C+e_2%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
We can notice several things in this basis.
a) All the vectors in 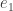

![\left[ \begin{array}{c} a \\ b \end{array} \right] = a \times \left[ \begin{array}{c} 1 \\ 0 \end{array} \right] + b \times \left[ \begin{array}{c} 0 \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a+%5C%5C+b+%5Cend%7Barray%7D+%5Cright%5D+%3D+a+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+%2B+b+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
b) The vectors
c) More interestingly, the two vectors
d) We can also notice that this basis corresponds to the standard x-y axes.
An important thing to note is that a vector space might have more than one basis. There are common techniques like Gram-Schmidt to generate Orthogonal sets of vectors. For eg , other valid basis for
![\left( \left[ \begin{array}{c} 1 \\ 1 \end{array} \right], \left[ \begin{array}{c} 1 \\ -1 \end{array} \right] \right) , \left( \left[ \begin{array}{c} 1 \\ 1 \end{array} \right], \left[ \begin{array}{c} -1 \\ 2 \end{array} \right] \right)](https://s0.wp.com/latex.php?latex=%5Cleft%28+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D%2C+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+-1+%5Cend%7Barray%7D+%5Cright%5D+%5Cright%29+%2C+%5Cleft%28+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D%2C+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+-1+%5C%5C+2+%5Cend%7Barray%7D+%5Cright%5D+%5Cright%29+&bg=ffffff&fg=333333&s=0&c=20201002)
Change Of Basis
So why did we discuss basis so much ? The reason is that PCA can be considered as a process of finding a new basis which is a linear combination of the original basis such that the inherent structure of points becomes more clear. Most of the time the standard basis (which is the x-y axes) makes a lousy basis. Again, let us see a picture to clarify this idea.

This image is very similar to the previous image. As before, the red lines are the x-y axes and the green crosses are the points. But what are the blue lines ? They are two axes which are perpendicular to each other but have the nice property that they bring out the internal structure more clearly. In other words, they are the new basis. Let us refer them as 
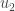
How is this new basis related to the original basis ? We get the new basis by rotating the original basis by 45 degrees. Remember, rotation, stretching and shrinking of the constituent vectors are all valid linear transformations.
Why is this new basis better than the old one ? Because , in this new basis the original point become (1,0), (2,0) and so on. So we only need one number to represent a point instead of the two in the original basis. We can also think that we have projected points in 2-dimensions to 1-dimension and have got the benefits of compression ! But we know that we can still get all the points back if needed.
A Dose of Real World
So far we have been living in the ideal world where the sensors gave us perfect data. But in real world , the sensors usually give the data with some noise. So let us take a look at the plot where a gaussian noise is added to the points.

So whatever we discussed above still holds but with slight modifications. Since the data was in 2 dimensions, to get a compression we need to project the points to 1 dimension. So we have to choose to project the points onto one of the axes (basis). How do we select the which axis to project on ? Since the points have noise in them , we need to project the points on to the axis which minimizes the projection error. Let us consider both the cases :
[Image Credit : The following 3 images are obtained from Stanford Prof Andrew Ng‘s Machine Learning course : Lecture notes on PCA ]
Case 1: Here we project on the first vector(axis) 
Case 2: Here we project on the first vector(axis) 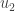


Which projection did you prefer ? I am sure you would have preferred the first projection intuitively. Algorithmically too that is the correct answer. The projection onto vector
Alternate View Of PCA
So far we have discussed PCA in terms of change of basis. There is an alternate way of looking at it . This way is slightly less intuitive but is very useful when you want to prove the optimality of PCA or derive formulas for PCA. The new idea is to look at the variance.
Let us take a look at the points again. 
We have to select one of the axis onto which we want to project the points. Which axis should you select ? From the image , vector
An alternate reasoning is that the original points will be along the direction of highest variance and the noise will be along the direction of the lesser variance. This is because, noise by definition is usually much smaller compared to original data points. Since
There is a formal proof that shows that minimizing the projection error and maximizing the variance are equivalent. We will skip the proof here.
Summary
The important points in this post are the following :
1. The standard basis is usually a bad one to store data.
2. PCA tries to find a new basis such that the projection error is minimized.
3. Alternate way to look at PCA is that it finds a vector to project which is in the direction of the highest variance.


[…] may ask what happened to PCA . Well, I still intend to write more on it but have not found enough time to sit and write it all. […]
When will part 2 be up?
Hello John,
I have not found enough time to write the part 2 and I also got distracted with other stuff. I will try to write the part 2 in a week or two.
Thanks for your comments !
very useful piece of information, thanks for posting this up 🙂
Need Part 2 soon!! My research work demands I read PCA 😀
Thank you for this great tutorial on PCA concept. I really enjoy from reading it.
I really enjoy your intuitive explanation of the PCA. Can’t wait to read the Part 2, 3, …. of it.
Thanks for your good job.
Thanks MOJ,
I am writing a more comprehensive post on PCA. I hope to have it ready by end of the month !
Thanks, i enjoyed it.
Thank you for the great post, Saravanan. I noticed that pictures for case 1 and case 2 should be switched.