K Nearest Neighbor (KNN from now on) is one of those algorithms that are very simple to understand but works incredibly well in practice. Also it is surprisingly versatile and its applications range from vision to proteins to computational geometry to graphs and so on . Most people learn the algorithm and do not use it much which is a pity as a clever use of KNN can make things very simple. It also might surprise many to know that KNN is one of the top 10 data mining algorithms. Lets see why this is the case !
In this post, I will talk about KNN and how to apply it in various scenarios. I will focus primarily on classification even though it can also be used in regression). I also will not discuss much about Voronoi diagram or tessellation.
KNN Introduction
KNN is an non parametric lazy learning algorithm. That is a pretty concise statement. When you say a technique is non parametric , it means that it does not make any assumptions on the underlying data distribution. This is pretty useful , as in the real world , most of the practical data does not obey the typical theoretical assumptions made (eg gaussian mixtures, linearly separable etc) . Non parametric algorithms like KNN come to the rescue here.
It is also a lazy algorithm. What this means is that it does not use the training data points to do any generalization. In other words, there is no explicit training phase or it is very minimal. This means the training phase is pretty fast . Lack of generalization means that KNN keeps all the training data. More exactly, all the training data is needed during the testing phase. (Well this is an exaggeration, but not far from truth). This is in contrast to other techniques like SVM where you can discard all non support vectors without any problem. Most of the lazy algorithms – especially KNN – makes decision based on the entire training data set (in the best case a subset of them).
The dichotomy is pretty obvious here – There is a non existent or minimal training phase but a costly testing phase. The cost is in terms of both time and memory. More time might be needed as in the worst case, all data points might take point in decision. More memory is needed as we need to store all training data.
Assumptions in KNN
Before using KNN, let us revisit some of the assumptions in KNN.
KNN assumes that the data is in a feature space. More exactly, the data points are in a metric space. The data can be scalars or possibly even multidimensional vectors. Since the points are in feature space, they have a notion of distance – This need not necessarily be Euclidean distance although it is the one commonly used.
Each of the training data consists of a set of vectors and class label associated with each vector. In the simplest case , it will be either + or – (for positive or negative classes). But KNN , can work equally well with arbitrary number of classes.
We are also given a single number "k" . This number decides how many neighbors (where neighbors is defined based on the distance metric) influence the classification. This is usually a odd number if the number of classes is 2. If k=1 , then the algorithm is simply called the nearest neighbor algorithm.
KNN for Density Estimation
Although classification remains the primary application of KNN, we can use it to do density estimation also. Since KNN is non parametric, it can do estimation for arbitrary distributions. The idea is very similar to use of Parzen window . Instead of using hypercube and kernel functions, here we do the estimation as follows – For estimating the density at a point x, place a hypercube centered at x and keep increasing its size till k neighbors are captured. Now estimate the density using the formula,
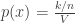
Where n is the total number of V is the volume of the hypercube. Notice that the numerator is essentially a constant and the density is influenced by the volume. The intuition is this : Lets say density at x is very high. Now, we can find k points near x very quickly . These points are also very close to x (by definition of high density). This means the volume of hypercube is small and the resultant density is high. Lets say the density around x is very low. Then the volume of the hypercube needed to encompass k nearest neighbors is large and consequently, the ratio is low.
The volume performs a job similar to the bandwidth parameter in kernel density estimation. In fact , KNN is one of common methods to estimate the bandwidth (eg adaptive mean shift) .
KNN for Classification
Lets see how to use KNN for classification. In this case, we are given some data points for training and also a new unlabelled data for testing. Our aim is to find the class label for the new point. The algorithm has different behavior based on k.
Case 1 : k = 1 or Nearest Neighbor Rule
This is the simplest scenario. Let x be the point to be labeled . Find the point closest to x . Let it be y. Now nearest neighbor rule asks to assign the label of y to x. This seems too simplistic and some times even counter intuitive. If you feel that this procedure will result a huge error , you are right – but there is a catch. This reasoning holds only when the number of data points is not very large.
If the number of data points is very large, then there is a very high chance that label of x and y are same. An example might help – Lets say you have a (potentially) biased coin. You toss it for 1 million time and you have got head 900,000 times. Then most likely your next call will be head. We can use a similar argument here.
Let me try an informal argument here - Assume all points are in a D dimensional plane . The number of points is reasonably large. This means that the density of the plane at any point is fairly high. In other words , within any subspace there is adequate number of points. Consider a point x in the subspace which also has a lot of neighbors. Now let y be the nearest neighbor. If x and y are sufficiently close, then we can assume that probability that x and y belong to same class is fairly same – Then by decision theory, x and y have the same class.
The book "Pattern Classification" by Duda and Hart has an excellent discussion about this Nearest Neighbor rule. One of their striking results is to obtain a fairly tight error bound to the Nearest Neighbor rule. The bound is
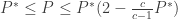
Where 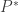
Case 2 : k = K or k-Nearest Neighbor Rule
This is a straightforward extension of 1NN. Basically what we do is that we try to find the k nearest neighbor and do a majority voting. Typically k is odd when the number of classes is 2. Lets say k = 5 and there are 3 instances of C1 and 2 instances of C2. In this case , KNN says that new point has to labeled as C1 as it forms the majority. We follow a similar argument when there are multiple classes.
One of the straight forward extension is not to give 1 vote to all the neighbors. A very common thing to do is weighted kNN where each point has a weight which is typically calculated using its distance. For eg under inverse distance weighting, each point has a weight equal to the inverse of its distance to the point to be classified. This means that neighboring points have a higher vote than the farther points.
It is quite obvious that the accuracy *might* increase when you increase k but the computation cost also increases.
Some Basic Observations
1. If we assume that the points are d-dimensional, then the straight forward implementation of finding k Nearest Neighbor takes O(dn) time.
2. We can think of KNN in two ways – One way is that KNN tries to estimate the posterior probability of the point to be labeled (and apply bayesian decision theory based on the posterior probability). An alternate way is that KNN calculates the decision surface (either implicitly or explicitly) and then uses it to decide on the class of the new points.
3. There are many possible ways to apply weights for KNN – One popular example is the Shephard’s method.
4. Even though the naive method takes O(dn) time, it is very hard to do better unless we make some other assumptions. There are some efficient data structures like KD-Tree which can reduce the time complexity but they do it at the cost of increased training time and complexity.
5. In KNN, k is usually chosen as an odd number if the number of classes is 2.
6. Choice of k is very critical – A small value of k means that noise will have a higher influence on the result. A large value make it computationally expensive and kinda defeats the basic philosophy behind KNN (that points that are near might have similar densities or classes ) .A simple approach to select k is set 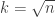
7. There are some interesting data structures and algorithms when you apply KNN on graphs – See Euclidean minimum spanning tree and Nearest neighbor graph .
8. There are also some nice techniques like condensing, search tree and partial distance that try to reduce the time taken to find the k nearest neighbor. Duda et al has a discussion of all these techniques.
Applications of KNN
KNN is a versatile algorithm and is used in a huge number of fields. Let us take a look at few uncommon and non trivial applications.
1. Nearest Neighbor based Content Retrieval
This is one the fascinating applications of KNN – Basically we can use it in Computer Vision for many cases – You can consider handwriting detection as a rudimentary nearest neighbor problem. The problem becomes more fascinating if the content is a video – given a video find the video closest to the query from the database – Although this looks abstract, it has lot of practical applications – Eg : Consider ASL (American Sign Language) . Here the communication is done using hand gestures.
So lets say if we want to prepare a dictionary for ASL so that user can query it doing a gesture. Now the problem reduces to find the (possibly k) closest gesture(s) stored in the database and show to user. In its heart it is nothing but a KNN problem. One of the professors from my dept , Vassilis Athitsos , does research in this interesting topic – See Nearest Neighbor Retrieval and Classification for more details.
2. Gene Expression
This is another cool area where many a time, KNN performs better than other state of the art techniques . In fact a combination of KNN-SVM is one of the most popular techniques there. This is a huge topic on its own and hence I will refrain from talking much more about it.
3. Protein-Protein interaction and 3D structure prediction
Graph based KNN is used in protein interaction prediction. Similarly KNN is used in structure prediction.
References
There are lot of excellent references for KNN. Probably, the finest is the book "Pattern Classification" by Duda and Hart. Most of the other references are application specific. Computational Geometry has some elegant algorithms for KNN range searching. Bioinformatics and Proteomics also has lot of topical references.
After this post, I hope you had a better appreciation of KNN !
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
If you liked this post , please subscribe to the RSS feed.
 to represent them. We will use the names seabass and salmon as it is more intuitive.
to represent them. We will use the names seabass and salmon as it is more intuitive.  which basically give the probability that the next fish in the conveyor is seabass or salmon. Of course, both of them have to sum to one. From the Bayesian perspective, this probability is usually obtained from prior (domain) knowledge. We will not talk about
which basically give the probability that the next fish in the conveyor is seabass or salmon. Of course, both of them have to sum to one. From the Bayesian perspective, this probability is usually obtained from prior (domain) knowledge. We will not talk about  is the probability of evidence. Eg lets say we got a fish (we dont know what it is yet) of length 5 inches. Now
is the probability of evidence. Eg lets say we got a fish (we dont know what it is yet) of length 5 inches. Now  . The interpretation is simple. This answers the question that if the fish is seabass what is the probability that it will have length
. The interpretation is simple. This answers the question that if the fish is seabass what is the probability that it will have length  inches (ditto salmon). Alternatively , what is the probability that a 5 inch seabass exists and so on. Or even how "likely" is a 5 inch seabass ?
inches (ditto salmon). Alternatively , what is the probability that a 5 inch seabass exists and so on. Or even how "likely" is a 5 inch seabass ?  . Intuitively, given that we have a fish of length
. Intuitively, given that we have a fish of length 
 say that the next fish is seabass and salmon otherwise. For eg let us say,
say that the next fish is seabass and salmon otherwise. For eg let us say,  . Let me attempt an informal reasoning – In the (sample) worst case, you will get first 40 as seabass, next 30 as salmon and next 30 as seabass. But you say first 30 as salmon and next 70 as seabass. In this hypothetical example you are only at the most 40% accurate even though you can theoretically do better.
. Let me attempt an informal reasoning – In the (sample) worst case, you will get first 40 as seabass, next 30 as salmon and next 30 as seabass. But you say first 30 as salmon and next 70 as seabass. In this hypothetical example you are only at the most 40% accurate even though you can theoretically do better.  then ALWAYS say seabass. Else ALWAYS say salmon. In this case the accuracy rate is
then ALWAYS say seabass. Else ALWAYS say salmon. In this case the accuracy rate is  . Conversely, the error rate is the minimum of both the prior probabilities. Convince yourself that this is the best you can do . It sure is counterintuitive to always say seabass when you know you will get salmon too. But we can easily prove that this is the best you can do "reliably".
. Conversely, the error rate is the minimum of both the prior probabilities. Convince yourself that this is the best you can do . It sure is counterintuitive to always say seabass when you know you will get salmon too. But we can easily prove that this is the best you can do "reliably".  .
. but we don’t know the prior probability. The decision rule here is : For each fish , find the appropriate likelihood values. If the likelihood of seabass is higher than that of salmon , say the fish is seabass and salmon otherwise.
but we don’t know the prior probability. The decision rule here is : For each fish , find the appropriate likelihood values. If the likelihood of seabass is higher than that of salmon , say the fish is seabass and salmon otherwise.  else decide salmon .
else decide salmon . else decide salmon . This rule is very important and is called as Bayes Decision Rule.
else decide salmon . This rule is very important and is called as Bayes Decision Rule. 
 else decide salmon.
else decide salmon. 
